Question:
What information is sent along when I post a job to the Calculation Engine?
Answer:
It is important to realize that, at all times, all metadata (i.e. strain descriptive information) stored in the BioNumerics database remains local. When a user launches a job on the Calculation Engine, only the following information is sent:
- Calculation Engine project name and password
- BioNumerics database name
- BioNumerics user name (defaults to _DefaultUser_)
- Experiment type name
- Entry key
- Sequence read set link (if needed)
- Genome sequence (if needed)
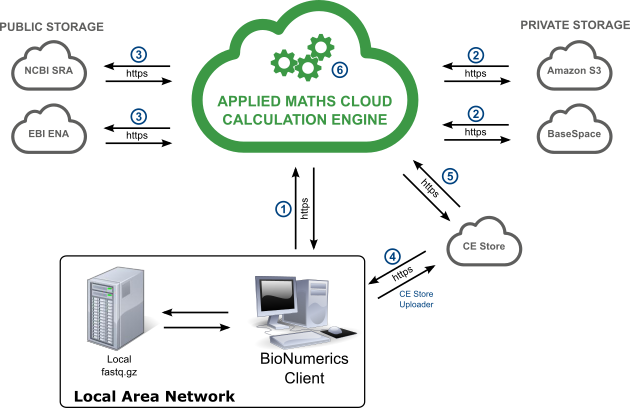
We always use secure connections (HTTPS) when private data are transmitted. The communication between the different components can be summarized as follows (numbers refer to the numbering used in the figure below):
- Communication between BioNumerics and the Calculation Engine is exclusively over HTTPS. Project credentials are required.
- Data transfer between the Calculation Engine and private data storage (S3 buckets, BaseSpace) is over HTTPS only.
- Communication between the Calculation Engine and public data storage (NCBI SRA, EBI ENA) could be over an unsecured HTTP connection since the data is public anyway.
- Local fastq.gz files are either on the BioNumerics client computer or on a file server within the LAN. Upload occurs via the CE Store Uploader over HTTPS.
- Communication between the Calculation Engine and CE Store is over HTTPS.
- All internal components of the Calculation Engine (Calculation Engine service, HPC cluster for calculations, nomenclature service) are on a private Amazon network.
Package(s):
BIONUMERICS
Applicable for:
Version 7.5 - 8.1