Multilocus sequence typing (MLST) is a molecular typing technique whereby a number of well chosen housekeeping genes (loci) are sequenced, usually in part.
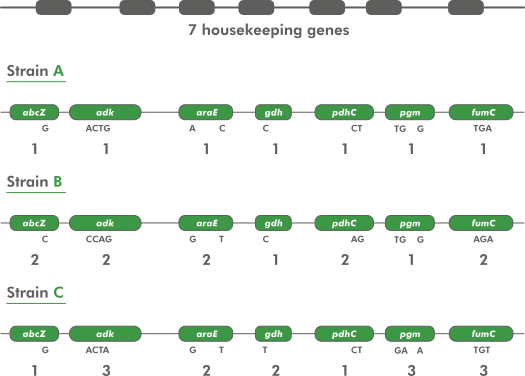
In a typical MLST approach, recombination is expected to occur with a much higher frequency than point mutations. Therefore, one does not look at the total sequence similarity between strains. Instead, each sequence for a given locus is screened for identity with already known sequences for that locus. If the sequence is different, it is considered to be a new allele and is assigned a unique (arbitrary) allele number. In case seven housekeeping genes are studied, each strain is thus characterized by a profile of seven allele numbers. The allelic profiles can be considered as a character set of 7 categorical characters. MLST has been used successfully to study population genetics and reconstruct micro-evolution of epidemic bacteria and other micro-organisms.
MLST in BIONUMERICS
Through the availability of an MLST plugin, the BIONUMERICS software is widely used for the storage and analysis of MLST sequences. BIONUMERICS automatically analyses batches of sequence trace files, connects to online MLST databases, retrieves corresponding allele numbers, sequence types as well as available clonal complex information. BIONUMERICS can process hundreds of isolates in only seconds. Results are stored in the database and are available for statistical and population analysis, clustering, partitioning, identification using BIONUMERICS' impressive set of analysis tools.
Easy MLST database setup
An MLST database can be easily set up for e.g. E. coli, Salmonella enterica, Klebsiella pneumoniae, Campylobacter, Acinetobacter baumannii, Pseudomonas aeruginosa or any other organism available from an online repository such as the mlst.net or pubmlst.org website, simply by selecting the organism from a list. BIONUMERICS can download alleles, trimming positions and MLST types locally and update its database at startup or fetch data for each analysis from web services. Alternatively, the user can set up own MLST schemes.
Setup scheme:

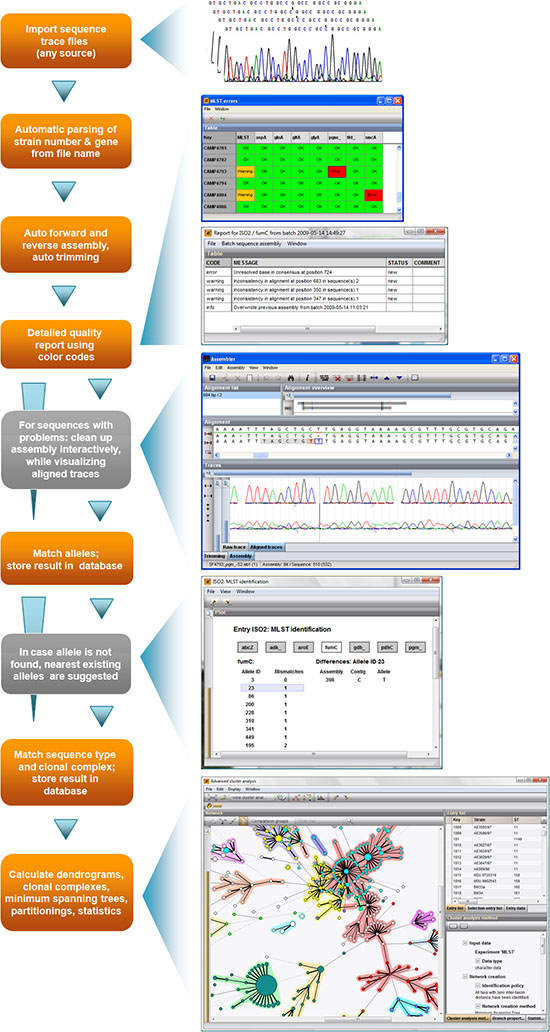
Fully automatic processing workflow
- Automatic import and assembly of batches of sequencer trace files from various sources (AB, Beckman, Amersham, FASTA); file names are parsed into strain and gene information using a parsing definition.
- Consensus sequences are automatically trimmed using start and stop signatures and placed in the right direction.
- When the batch assembly is finished, an overview report is shown, listing status of each strain/gene combination.
- Double-click on a problem contig to display the detailed information window.
- Double-click on a particular problem to open the Assembler with the problem position selected.
- For each problem position, show nearest existing alleles and suggested bases - easy verification with chromatograms.
- Alleles and MLST types can be identified by real-time connection to MLST server database, or by comparing to locally stored allele database (faster). In the latter case, local database can be updated automatically at startup.
- Allele and MLST type information for own strains is stored in the database and can be updated at any time for a selection of strains. BIONUMERICS will prompt you for any change in allele/MLST type definition that has occurred in the MLST server database.
- Calculate population modelling networks in the finest and most comprehensive cluster analysis application available today, using standard or custom priority rules and with branch significance support indication.
- Calculate and display partitioning for clonal complexes and use BIONUMERICS' rich set of statistics tools.
Workflow scheme: